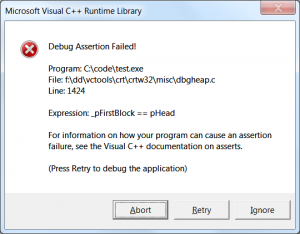
I was really irritated today when after uninstalling one edition of VS2015 and then installing another one, the setup program didn’t allow me to change the installation path. I manually uninstalled any leftover components from Add/remove programs and verified that the previous installation directory is empty. Still, the setup insisted that I install in the same location as the previous one. I searched the registry and sure enough, found some leftover keys with the old path. Most of them was here:
HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Installer\UserData\S-1-5-18\Components
At first I tried to clean them up manually but there were a lot of them, basically one entry for every previously installed file (of some components). As I said I uninstalled every VS2015 component so I didn’t care about deleting MSI entries. Finally I wrote a small C# program that did the trick:
using System;
using Microsoft.Win32;
namespace VsCleanup
{
class Program
{
static int Main(string[] args)
{
Console.WriteLine("Enter the old VS path to purge from the registry:");
string OldPath = Console.ReadLine().Trim().ToLowerInvariant();
string RootKeyName = @"SOFTWARE\Microsoft\Windows\CurrentVersion\Installer\UserData\S-1-5-18\Components";
RegistryKey RootKey = Registry.LocalMachine.OpenSubKey(RootKeyName, true);
if (RootKey == null)
{
Console.WriteLine("Unable to open registry, make sure to run as admin");
return 1;
}
var SubkeyNames = RootKey.GetSubKeyNames();
foreach (var SubkeyName in SubkeyNames)
{
var Subkey = RootKey.OpenSubKey(SubkeyName, true);
var ValueNames = Subkey.GetValueNames();
bool Delete = false;
foreach (var ValueName in ValueNames)
{
if (Subkey.GetValueKind(ValueName) == RegistryValueKind.String)
{
var Value = Subkey.GetValue(ValueName) as string;
if (Value.ToLowerInvariant().StartsWith(OldPath))
{
Console.WriteLine("{0}: {1}", SubkeyName, Value);
Delete = true;
break;
}
}
}
Subkey.Close();
if (Delete)
RootKey.DeleteSubKeyTree(SubkeyName, true);
}
RootKey.Close();
return 0;
}
}
}
Obviously, change the path to whatever you have/had (check in regedit manually first if not sure). It also works for VS 2013.
[Update: 2016-07-26]
Improved the code a bit. Also an important note: make sure to build the program as x64 if you’re on a 64-bit OS, otherwise you may get hit by registry redirection and it won’t work.